|
無縫替代GPU,讓FPGA加速你的AI推理!
如今,基於深度學習(DL)的人工智能(AI)應用越來越廣泛,不論是在與個人消費者相關的智能家居、智能駕駛等領域,還是在視頻監控、智慧城市等公共管理領域,我們都能看到其身影。
眾所周知,實施一個完整的AI應用需要經歷訓練和推理兩個過程。所謂“訓練”,就是我們要將大量的數據代入到神經網絡模型中運算並反复迭代,“教會”算法模型如何正確的工作,訓練出一個DL模型。而接下來,我們就可以利用訓練出來的模型來在線響應用戶的需求,根據輸入的新數據做出正確而及時的決策判斷,這個過程就是“推理”。

通常來講,一個AI應用中“訓練”只需要做一次——有時這個工作會交給第三方專業的且有充沛算力資源的團隊去做,而應用開發工程師要做的則是將訓練好的模型部署到特定的硬件平台上,滿足目標應用場景中推理過程的需要。由於推理過程會直接聯繫最終用戶,推理的準確性和速度也會直接影響到用戶體驗的好壞,因此如何有效地為AI推理做加速,也就成了當下開發者普遍關心的一個熱門的話題。
AI推理加速,FPGA勝出!
從硬體架構來看,可以支持AI推理加速的有四個可選方案,它們分別是:CPU、GPU、FPGA和ASIC,如果對這幾類器件的特性進行比較,會發現按照從左到右的順序,器件的靈活性/適應性是遞減的,而處理能力和性能功耗比則是遞增的。
CPU是基於馮∙諾依曼架構,雖然其很靈活,但由於存儲器訪問往往要耗費幾個時鐘週期才能執行一個簡單的任務,延遲會很長,應對神經網絡(NN)這種計算密集型的任務,功耗也會比較大,顯然最不適合做AI推理。
GPU具有強大的數據並行處理能力,在做海量數據訓練方面優勢明顯,而推理計算通常一次只對一個輸入項進行處理的應用,GPU並行計算的優勢發揮不出來,再加上其功耗相對較大,所以在AI推理方面也不是最優選擇。
從高性能和低功耗的角度來看,定制的ASIC似乎是一種理想的解決方案,但其開發週期長、費用高,對於總是處於快速演進和迭代中的DL和NN算法來說,靈活性嚴重受限,風險太大,在AI推理中人們通常不會考慮它。

所以我們的名單上只剩下FPGA了。這些年來大家對於FPGA快速、靈活和高效的優點認識越來越深入,硬體可編程的特性使其能夠針對DL和NN處理的需要做針對性的優化,提供充足的算力,而同時又保持了足夠的靈活性。今天基於FPGA的異構計算平台,除了可編程邏輯,還會集成多個Arm處理器內核、DSP、片上存儲器等資源,DL所需的處理能力可以很好地映射到這些FPGA資源上,而且所有這些資源都可以並行工作,即每個時鐘週期可觸發多達數百萬個同時的操作,這對於AI推理是再合適不過了。
與CPU和GPU相比,FPGA在AI推理應用方面的優勢還表現在:
• 不受數據類型的限制,比如它可以處理非標準的低精度數據,從而提高數據處理的吞吐量。
• 功耗更低,針對相同的NN計算,FPGA與CPU/GPU相比平均功耗低5~10倍。
• 可通過重新編程以適應不同任務的需要,這種靈活性對於適應持續發展中的DL和NN算法尤為關鍵。
• 應用範圍廣,從雲端到邊緣端的AI推理工作,都可勝任。
總之一句話,在AI推理計算的競爭中,FPGA的勝出沒有懸念。
GPU無縫對接,FPGA即插即用
不過,雖然FPGA看上去“真香”,但是很多AI應用的開發者還是對其“敬而遠之”,究其原因最重要的一點就是——FPGA上手使用太難了!
難點主要體現在兩個方面:
• 首先,對FPGA進行編程需要特定的技能和知識,要熟悉專門的硬體編程語言,還要熟練使用FPGA的特定工具,才能通過綜合、佈局和佈線等複雜的步驟來編譯設計。這對於很多嵌入式工程師來說,完全是一套他們所不熟悉的“語言”。
• 再有,因為很多DL模型是在GPU等計算架構上訓練出來的,這些訓練好的模型移植、部署到FPGA上時,很可能會遇到需要重新訓練和調整參數等問題,這要求開發者有專門的AI相關的知識和技能。
如何能夠降低大家在AI推理中使用FPGA的門檻?在這方面,Mipsology公司給我們帶來了一個“驚喜”——該公司開發了一種基於FPGA的深度學習推理引擎Zebra,可以讓開發者在“零努力(Zero Effort)”的情況下,對GPU訓練的模型代碼進行轉換,使其能夠在FPGA上運行,而無需改寫任何代碼或者進行重新訓練。
這也就意味著,調整NN參數甚至改變神經網絡並不需要強制重新編譯FPGA,而這些重新編譯工作可能需要花費數小時、數天,甚至更長時間。可以說,Zebra讓FPGA對於開發者成了“透明”的,他們可以在NN模型訓練好之後,無縫地從CPU或GPU切換到FPGA進行推理,而無需花費更多的時間!
目前,Zebra可以支持Caffe、Caffe2、MXNet和TensorFlow等主流NN框架。在硬體方面,Zebra已經可以完美地支持Xilinx的系列加速卡,如Alveo U200、Alveo U250和Alveo U50等。對於開發者來說,“一旦將FPGA板插入PC,只需一個Linux命令”,FPGA就能夠代替CPU或GPU立即進行無縫的推斷,可以在更低的功耗下將計算速度提高一個數量級。對用戶來說,這無疑是一種即插即用的體驗。。
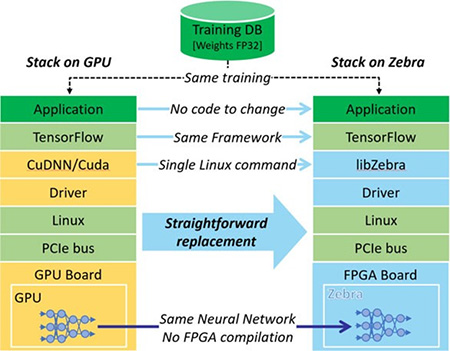
圖1,Zebra可適應由GPU加速器訓練的NN,並無縫地在FPGA上部署
強強聯手,全生態支持
更好的消息是:為了能夠加速更多AI應用的落地,安富利亞洲和 Mipsology 達成了合作協議,將向其亞太區客戶推廣和銷售 Mipsology 這一獨特的 FPGA 深度學習推理加速軟體 —— Zebra。
這對於合作的雙方無疑是一個雙贏的局面:對於Mipsology來說,可以讓Zebra這個創新的工具以更快的速度覆蓋和惠及更多的開發者;對安富利來說,此舉也進一步擴展了自身強大的物聯網生態系統,為客戶帶來更大的價值,為希望部署DL的客戶提供一整套全面的服務,包括硬體、軟體、系統集成、應用開發、設計鍊和專業技術。

安富利推理加速成功應用案例:智能網絡監控平台AI Bluebox
想學習更多Zebra 軟體的“神奇之處”,掌握如何基於Zebra 軟體、安富利服務器以及賽靈思的Alveo加速卡,方便有效地安裝正確的CNN 神經網絡推理加速器,深入地體驗基於Zebra 的解決方案如何無縫替代GPU 板卡做AI 推理?安富利攜手 Mipsology 加速 AI 解決方案部署 網絡研討會,技術大咖為您一一解答!
閱讀原文
|
