|
如何在雲端、網 絡和邊緣部署高效的人工智能深度學習推斷
作者:賽靈思戰略市場開發高級經理 Daniel Eaton
深度學習 AI 應用是解鎖生產力新時代的關鍵,人類的創造力能夠通過機器得到提高與增強。我們致力於將大量培訓數據和海量數學運算用於全面訓練每個神經網絡。訓練可使用大規模批處理功能離線進行,歷時數天。經過訓練的網絡要投入部署,那就面臨嚴格得多的時限要求。
為了納入 AI 處理功能,數據中心將需要部署更新的服務器,但空間的局限和功耗的的問題都是阻礙AI 部署的關鍵問題。與此同時,客戶期望獲得即時響應,這就需要確保極低時延。

在汽車駕駛輔助系統或自動駕駛汽車等用例中,必須確保生命安全,這不僅要求最大限度地降低時延,確保可靠的實時響應也至關重要。與此同時,數據中心的規模和功耗要求甚至更嚴,重量和散熱問題也是他們必須要考慮的問題。特斯拉近期舉辦自動駕駛日活動,介紹他們為什麼選擇自建芯片,相對於 GPU 而言能夠實現低功耗(小於 100 瓦)和低時延(一個批處理大小)的結合優勢。

隨著 AI 不斷在越來越多的領域得到推廣,並助力更快地解決挑戰性問題,已部署的神經網絡也面臨著更高的性能要求。
歷久彌新的高效推斷
無論我們討論的是雲端 AI 還是 AI 在汽車等領域的嵌入式應用,滿足新型應用需求的推斷引擎都必須確保低時延、低功耗和小尺寸。
將經過訓練的神經網絡成功用於執行現實環境的推斷,不僅需要適當的調整優化,還需要認真考慮處理平台,從而可以在功耗、尺寸和散熱等常見限制性條件下,確保所需的性能(通常指響應時間或時延)。隨著 AI 商業部署的推廣以及最終用戶需求的提升,處理器芯片廠商都在加強高端器件架構的開發以滿足相關要求。
一些最新型芯片面向自動駕駛等應用領域,採用結合 CPU 和應用處理器核的混合架構,並搭配大量 GPU 進行數學運算。儘管片上資源可用,但架構是固定的,因此開發者受制於不靈活的存儲器接口寬度和數據解析度。 8 位整數數學通常是最小寬度,但深度學習算法能以更低的解析度有效操作數據,有時甚至低至 2 位或 1 位。不靈活的 CPU 或 GPU 計算架構越來越難以滿足神經網絡性能要求,我們需要更靈活的架構調整解析度及核數量,從而實現最佳計算性能與功耗。
調整優化受訓練的神經網絡並在目標處理器中高效實施已經非常困難,新型更高效神經網絡的開發源源不斷,更是超越了芯片的發展速度。項目一開始基於最先進的技術,但很可能在部署時技術就已經過時了。不過,部署時最尖端的神經網絡技術,在現有處理器架構中幾乎肯定無法表現良好。
可配置的 AI 加速
為應對性能、功耗和麵向未來靈活性的挑戰,開發團隊目前正在利用 FPGA 提供的靈活應變優勢來構建 AI 加速器。
FPGA 能配置成百上千乃至成千上萬個高度並行化的計算單元,最低支持單位解析度,並且為了消除瓶頸還可定制存儲器接口。此外,FPGA 可方便地再編程,這就能讓開發者在芯片迭代之間更靈活地升級神經網絡結構,並跟上技術發展的步伐。
2017 年,賽靈思收購了 AI 專業公司深鑑科技 (DeePhi Tech),此後加大了先進的調整優化工具和 IP 開發力度,從而可以更好地在 FPGA 中部署神經網絡。通過刪除不具備影響力的近零訓練權重,調整優化可精簡神經網絡,並發現可最大限度減少計算操作數量、降低功耗的網絡組織方式。深鑑科技的神經網絡優化技術經過優化後運行在 FPGA 上,能減少多達九成權重,同時實現可接受的圖形識別精度。性能提速高達 10 倍,能效也得到大幅提升。
從雲端到邊緣
自動駕駛技術是一個很好的例子,說明了人們對低時延、小尺寸、少重量和低功耗的迫切需求。雷達或攝像頭檢測到的對象(如車輛、騎行者、行人等)需要在瞬間加以識別。眾所周知,人類在四分之一秒的時間之內就能對視覺輸入做出反應,因此,自動駕駛系統所需的視覺識別功能至少也應達到相同的速度,甚至應當更快。要達到人類駕駛員的水平,就整個檢測—識別—響應過程而言,系統應當能在 1.5 秒之內做出緊急制動決定。

賽靈思近期宣布同奔馳開展研發合作,實施基於高性能 FPGA 的深度學習處理器,用來分析來自攝像頭、雷達和激光雷達的數據,實現駕駛員監控、車輛導引和防撞等功能。兩家公司的專家聯手基於高度自適應的汽車平台上實施 AI 算法,並將為奔馳的神經網絡優化深度學習處理器技術。該技術可以最大限度地降低時延,同時還能實現較高的功率效率,確保系統在汽車有限的散熱條件下可靠地工作。
此外,在數據中心領域,FPGA 也能支持深度學習加速器,其單位功耗性能水平大大超越標準的的GPU 處理器,韓國SK 電訊將Kintex® UltraScale™ FPGA 作為數據中心的AI 加速器,從而成功提升了其語音助理NUGU 的性能。這是韓國電信產業首次部署 AI,相對於傳統的 GPU 處理器,SK 的自動語音識別 (ASR) 應用速度提升高達 500%。單位功耗性能提升 16 倍。此外,現有的僅使用 CPU 的服務器在採用加速器後,處理多個語音通道時能顯著降低 SKT 的總體擁有成本 (TCO)。
另一個例子就是最新型 AI 家庭安全功能。作為與新興市場領域中領先企業之一 Tend Insights 聯合開發的雲平台的一部分,由 FPGA 加速的低時延推斷能夠支持更加智能的監控功能和創新服務,如居家護理等。安裝在家裡各個位置的攝像頭具備識別有關事件的基本功能,並能夠將畫面上傳到在雲端運行的基於 FPGA 的 AI 加速器中。這些加速器可通過一系列API 訪問(本例中是作為賽靈思機器學習套件(ML Suite) 硬件編譯器的一部分),區分哪些人是家庭成員、哪些是陌生人,哪些是家庭寵物,哪些是其他動物,從而判斷是否存在威脅並發出警報。內部攝像頭的畫面幀在業主同意下進行分析,能夠判斷家庭成員是否面臨困難,比如老人是否摔倒了需要幫助。隨後,該系統能夠發出呼救,包括撥打指定家庭成員的電話或尋求專業護理機構的幫助。
AI 也在眾多其他場合下發揮作用,用來進行複雜的模式匹配和圖像識別,并快速獲得結果。這包括基因組分析,加速醫療診斷和治療。使用 FPGA 加速 AI 推斷已將病人基因組測序和異常識別所需時間從 24 小時縮短至大約 20-30 分鐘。然後就是原子研究,核聚變實驗畫面捕獲涉及極高清圖形,每幀動輒高達 1 億像素,而且需要在 25ms 之內處理。這種挑戰需要引入低時延神經網絡探測器,傳統 CPU 推斷根本無法應對。事實上,傳統方法相差甚遠。 FPGA 已經在幫助科學家獲得他們所需的答案了。

結論
AI 最近才成為一個切實可行的解決方案,但在人們的日常工作生活中已經開始發揮重要作用。降低運營成本、縮短客戶等待時間、打造新的增值服務機遇,這些潛力讓商業機構深感激動,同時也加大了性能提升的壓力,需要降低時延、功耗和成本。
創建 AI 有兩大要素,一是訓練某種類型的神經網絡,讓其盡可能符合現有任務要求;二是對經過訓練的網絡進行調整優化,作為推斷引擎在適當的處理器上實施。
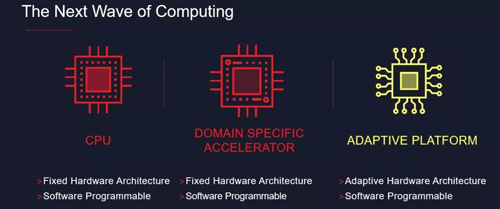
FPGA 架構的靈活性和高性能,加上高性能的實施優化工具(如ML Suite 硬件編譯器和Deephi 優化器),再加上實施最新神經網絡架構帶來的可再配置性使其無需等待芯片更新,這些都是在雲端、網絡或網絡邊緣實現AI 推斷加速的關鍵因素。
閱讀原文
|
