|
PYNQ & HLS | 跟著北大CECA學FPGA加速器設計
Pooterko Xilinx學術合作 ,4月28日
本文的目標是幫助對於深度學習硬件加速器設計感興趣的朋友快速上手基於FPGA的深度學習加速器設計。
準備
以下是閱讀本文的基礎,請做好下列基礎準備後再上手加速器設計:
1.C語言設計:熟練掌握C語言語法。
2.計算機體系結構知識:參考書《計算機組成與設計》,不需要熟讀全書,但要對一些加速器設計相關的基礎概念有比較清晰的理解和認識,如流水線、數據並行等。
高層次綜合
利用高層次綜合工具,開發者只需要編寫高級語言的代碼完成程序功能,就能將高級語言編寫的代碼綜合成相同功能的RTL級實現(基於Verilog或VHDL)。開發者還可以通過添加一些pragma的方式來指示和調整高層次綜合工俱生成的硬件模塊的架構。整體而言,利用高層次綜合工具進行FPGA硬件開發的過程,應該是利用軟件語言的表達來描述硬件模塊的過程。目前,高層次綜合的代碼都是基於C/C++/OpenCL的,所以對於沒有硬件設計基礎的朋友來說,利用高層次綜合工具可以大幅度地降低學習難度,縮短開發週期,加快設計迭代速度。
3天入門實例
我們需要使用一個簡單的實例來進行入門學習。既然目標是讓大家快速上手深度學習加速器的硬件設計,那麼我們的實戰示例就選擇使用目前最火爆、最具代表性的深度學習算法——卷積神經網路(CNN)。我們選取卷積神經網絡前向計算中耗時最長的捲積操作作為我們加速設計的目標。接下來,需完成以下步驟:
1. 準備工作(1天)
下載Xilinx Vivado HLS或Xilinx SDx工具鏈,利用官方User guide熟悉軟件工具的使用,包括:新建工程、配置工程參數、綜合流程等。
2. 軟件實現(1天)
實現卷積層的軟件版本(C語言版本),並封裝成一個頂層函數。綜合實現,結合高層次綜合工具的report和analyze工具分析理解所生成的硬件架構和預計性能。卷積運算的流程如下圖所示:
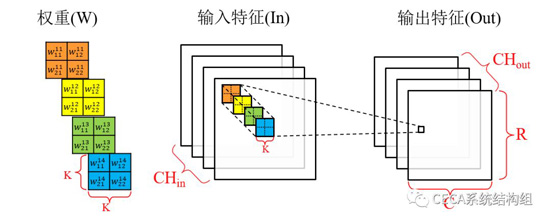
整個卷積層的輸入是CHin張輸入特徵圖,輸出是CHout張輸出特徵圖,每張輸出特徵圖的大小為R×C。由於每一個“輸入-輸出”特徵圖對都有一個特定的捲積核用於卷積計算,所以總共有CHout×CHin個卷積核,每個卷積核的大小為K×K。在進行卷積計算的過程中,每個卷積核滑過各自的輸入特徵圖,並使用當前滑過的窗口中的輸入特徵與卷積核內的權重完成捲積計算(對應位置相乘,所有乘積累加),卷積的結果會累加到對應位置的輸出特徵上。因此,卷積計算的算法流程如下式所示:
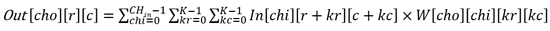
相應地,卷積層前向計算的軟件版本代碼如下所示:

本質上來說,卷積層前向計算的流程就是一個嵌套的6重循環,而在循環的最內層進行的是乘累加運算。在我們的示例中,我們用如下代碼放入HLS工具中進行綜合分析:

其中,數據類型我們指定為單精度浮點(float),網絡層參數如下:

設置硬件週期為10ns,在Vivado HLS 2018.3中綜合得到該模塊運行延遲和資源開銷報告,其中延遲報告為251376個時鐘週期(具體數字可能略有差異)。
3. HLS優化(1天)
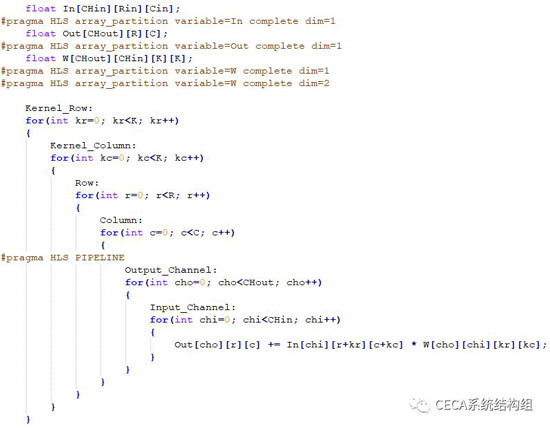
在實現了卷積層的軟件版本後,我們可以嘗試對該代碼進行硬件並行優化,這裡我們用一個簡單的加速設計來幫助大家理解HLS的優化方法。從上面的捲積流程分析,我們不難發現:卷積計算過程中,不同通道的輸入/輸出特徵圖在參與計算的過程中沒有數據依賴關係,因而是可以並行處理的。在我們這個簡單的小例子中,我們計劃將輸入通道(Input Channel Loop)和輸出通道(Output Channel Loop)這兩個維度進行並行加速優化。因此,我們想要實現的加速器核心模塊示意圖如下:
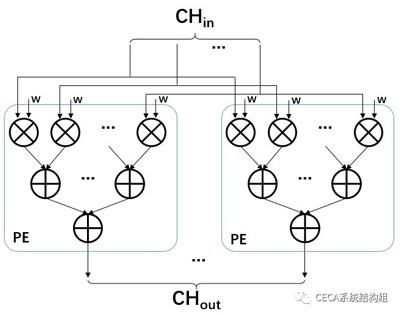
我們使用CHin個並行的乘法器來並行處理不同通道的輸入特徵與其對應權重的乘法,這些並行乘法的乘積累加到一起,即為一個輸出通道的的捲積結果,這裡,我們把該模塊稱為一個處理單元(Processing Element,簡稱PE,即上圖中藍色框部分)。一個PE只負責一個輸出通道的捲積計算,我們可以把PE複製多份,形成上圖的結構,來並行處理所有輸出通道的捲積計算。總結來說,這個加速器調用一次可以並行處理包含CHin個輸入特徵點和CHout個輸出特徵點的捲積計算,而其中所有輸入特徵點都屬於不同的輸入通道,輸出特徵點也分屬於不同的輸出通道。要完成整個卷積層6重循環的計算,我們需要重複多次調用這個加速器。現在我們就需要使用HLS來將上文設計的加速器描述出來,主要進行的代碼改動包括以下三部分:
循環重構:
由於我們的加速器是在輸入通道和輸出通道兩個維度進行並行化,完成捲積計算需重複調用加速器多次,因此,我們需要將輸入通道循環和輸出通道循環放在最內層循環中。由於最內層的乘累加操作滿足結合律,卷積的6重循環的順序可以直接調整,而無需其它改動。
數組劃分:
從上面加速器設計我們可以看出,我們需要並行地訪問輸入特徵(In)、輸出特徵(Out)和權重(W),而對應的並行度分別為CHin、CHout和CHout×CHin。因此,在FPGA實現的時候,我們需要將這些數據劃分到多個RAM塊中以滿足並行訪問的需求。我們可以使用Array Partition來完成數組劃分,該pragma的具體語法請參考Xilinx官方文檔。
循環展開:
為了描述出我們的加速器在輸入通道和輸出通道兩個維度進行了並行優化,我們需要使用pragma UNROLL來將這兩個循環完全展開,pragma UNROLL的具體語法請參考Xilinx官方文檔。
綜合上述改動後,我們的代碼如下所示:
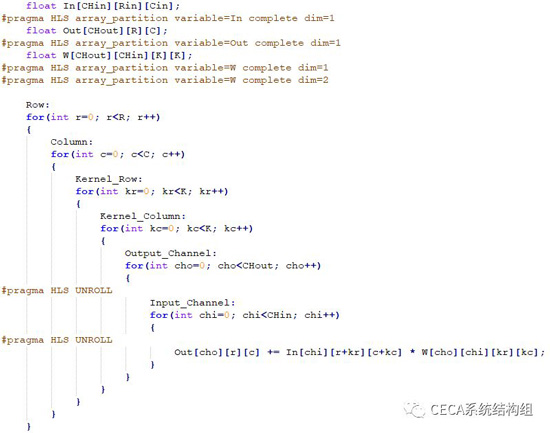
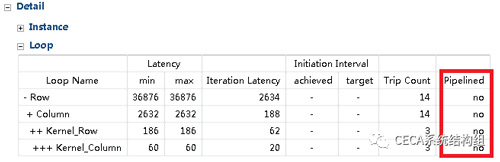
在HLS工具中重新綜合,我們可以發現延遲降到了36876個時鐘週期(具體數字可能略有差異),有了6.82倍的加速效果。但當我們仔細看HLS的綜合報告時可以發現,雖然我們實現了一個並行加速器,可是這個加速器調用並沒有流水化起來:
因此,我們可以嘗試進一步優化提升性能:使用pragma PIPELINE將加速器設計流水化起來,該pragma的具體語法請參考Xilinx官方文檔。在使用pragma PIPELINE以後,之前的pragma UNROLL可以去掉以精簡代碼,這是由於HLS工具會自動將需要流水化的循環內部的所有子循環展開,這個優化會在HLS工具的Console裡顯示。因此,我們的代碼調整如下:

在HLS工具中重新綜合,發現延遲降到了29993個時鐘週期(具體數字可能略有差異),性能進一步提升了22.95%。 HLS的綜合報告裡也顯示加速器調用也已經流水化了:

從上面的綜合報告我們可以發現一個細節,雖然整個循環已經流水化了,但是Initiation Interval卻仍然不是理想情況的1,即:不能做到每個週期都開始一個新的Iteration的計算。那麼問題出在哪裡呢?還有沒有進一步優化的空間呢?
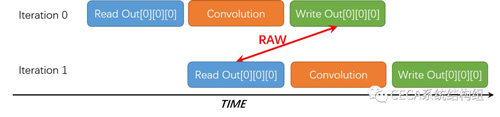
通過分析代碼和HLS工具的Warning我們可以發現,問題出在Out這個數組上。在我們的實現中,Out數組在內層循環的一個Iteration中參與了自加運算(+=),即:先被讀,後被寫。如下圖所示,在執行Iteration 0的時候(r=c=kr=kc=0),Out[0][0][0]先被讀,然後被寫;然而在接下來執行計算Iteration 1( r=c=kr=0, kc=1)的時候,仍然是Out[0][0][0]先被讀,然後被寫。因此,如果我們使用pragma PIPELINE進行性能優化,相鄰的這兩個Iteration都需要操作Out[0][0][0]這個位置的數據,從而產生寫後讀(RAW)的數據依賴,即:程序必須等待Iteration 0對Out[0][0][0]的寫操作完成後,才能開始執行Iteration 1。為了保證程序結果的正確性,HLS工具不會將這部分循環完全流水化,進而導致性能的下降。
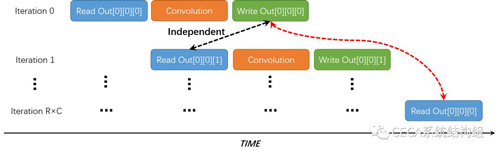
通過觀察我們可以發現:Out數組的在程序中的訪問位置,只和r、c這兩個循環變量相關,而和kr、kc無關。我們可以利用這一點解決RAW數據依賴的問題。為了能將內層循環的計算完全流水化,我們決定將Kernel Row和Kernel Column兩重循環移到外層。如下圖所示,將循環流水化時,相鄰Iteration所訪問的Out數組的數據位置是不同的,不存在數據依賴,可以流水執行;而有RAW數據依賴的Iteration將在很遠的時間點發生(R×C個Iteration之後),此時對於該位置的寫操作早已完成,讀操作可以正常進行。這樣一來,我們實現了一個完全流水化的硬件架構,提升了加速器的整體處理性能。
按照上述優化調整後的代碼如下:
在HLS工具中重新綜合,發現延遲降到了僅僅1782個時鐘週期(具體數字可能略有差異),相對於原始無優化版本的加速達到了141.06倍! HLS的綜合報告裡顯示加速器調用也已經完全流水化了:
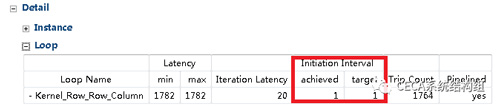
綜上,我們就完成了一個高效的捲積運算加速器,而基本上利用HLS工具設計FPGA硬件加速器的入門也就完成了。總結來說,使用HLS設計FPGA加速器的一般化設計流程如下:
1.熟悉並理解目標算法,通過軟件運行目標算法,分析性能瓶頸所在;
2.實現加速目標的軟件版本,分析其中可以並行、流水化的部分,並構想可行的硬件架構;
3.通過代碼重構,加pragma等方法在HLS工具中描述目標架構,此過程需注意保證改寫的代碼功能性上與原代碼嚴格保持一致;
4.調整硬件參數配置,最大化利用硬件資源(計算資源如DSP、存儲資源如BRAM)來最大化加速器的性能。
30天精通學習
在完成了上面的3天入門實例後,大家可以進一步學習和實踐FPGA加速器的設計,這一部分我們推薦大家利用3到4週的時間對相關知識進行詳細、系統的學習。高層次綜合的相關知識的學習我們推薦學習Xilinx公司推出的《Parallel Programming for FPGAs (中文版)》,該教程的下載地址是https://github.com/xupsh/pp4fpgas-cn。大家要仔細閱讀這本書,並配合https://github.com/xupsh/pp4fpgas-cn-hls中的代碼實例理解高層次綜合的代碼風格和pragma的使用方法。關於高層次綜合的pragma請參照Xilinx官方的pragma詳解加深理解和記憶。開發板方面,我們推薦使用Xilinx Pynq-Z2進行上板實踐。
結語
硬件加速器設計是一個長期的、需要大量經驗積累的工作。本文僅為讀者提供了一個快速入門上手設計的分享,想要設計高效的硬件加速器的讀者還需要多關注前沿領域、多閱讀頂級學術論文、多上手設計實踐,在發掘潛在加速需求的同時提升自身設計加速器架構的能力。本文側重入門知識分享,後續會考慮出進階版實例、論文分享、設計總結等,希望讀者能夠多多反饋意見。
致謝
感謝北京大學高能效計算與應用中心羅國傑教授和Xilinx大中華區教育與創新生態高級經理陸佳華先生對本文的校訂和支持。
CECA系統結構組簡介
北京大學高能效計算與應用中心(Center for Energy-Efficient Computing and Applications,簡稱CECA)成立於2010年。該中心是北京大學在“985工程”中建設的開展國際先進水平的高能效計算與應用研究的科研機構。該中心既是北京大學計算機系統結構學科的重要組成部分,又是一個交叉研究機構。 CECA系統結構組的主要研究方向包括:面向深度學習等應用的加速器系統架構設計,面向邊緣計算等新興應用的高能效系統研究,和基於新型存儲器的高能效存儲系統結構研究。
閱讀原文
|
